Distributed Training
Most models can be trained in a reasonable amount of time using a single GPU. Minimizing the “time to finish” is minimizing both the time the job spends running on the compute node and the time spend waiting in the queue.
Distributed training is imperative for larger and more complex models/datasets. Data parallelism is a relatively simple and effective way to accelerate training.
However, if you are effectively using the GPU then you may consider running on multiple GPUs. For more, look into how to conduct a scaling analysis.
Data vs Model Parallelism
There are two ways to distribution computation across multiple devices.
|
|
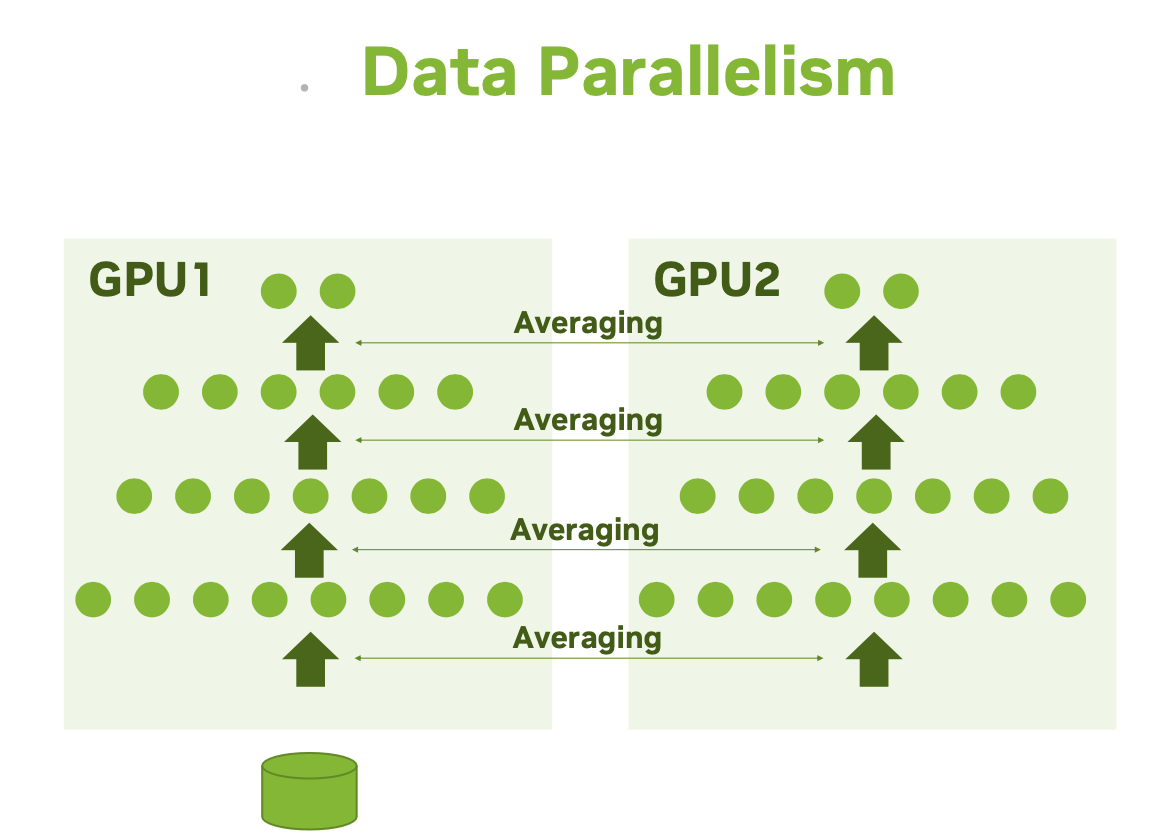
Data parallelism: A single model gets replicated on multiple devices. Each processes different batches of data, then they merge their results.
- The single-program, multiple data (SPMD) paradigm is used. That is, the model is copied to each of the GPUs. The input data is divided between the GPUs evenly. After the gradients have been computed they are averaged across all the GPUs. This is done in a way that all replicas have numerically identical values for the average gradients. The weights are then updated and once again they are identical by construction. The process then repeats with new mini-batches sent to the GPUs.
- For additional information: https://www.telesens.co/wp-content/uploads/2019/04/img_5ca570946ee1c.png
- There exists many variants, and they differ in how the different model replicas merge results, in whether they stay in sync at every batch or whether they are more loosely coupled, etc.
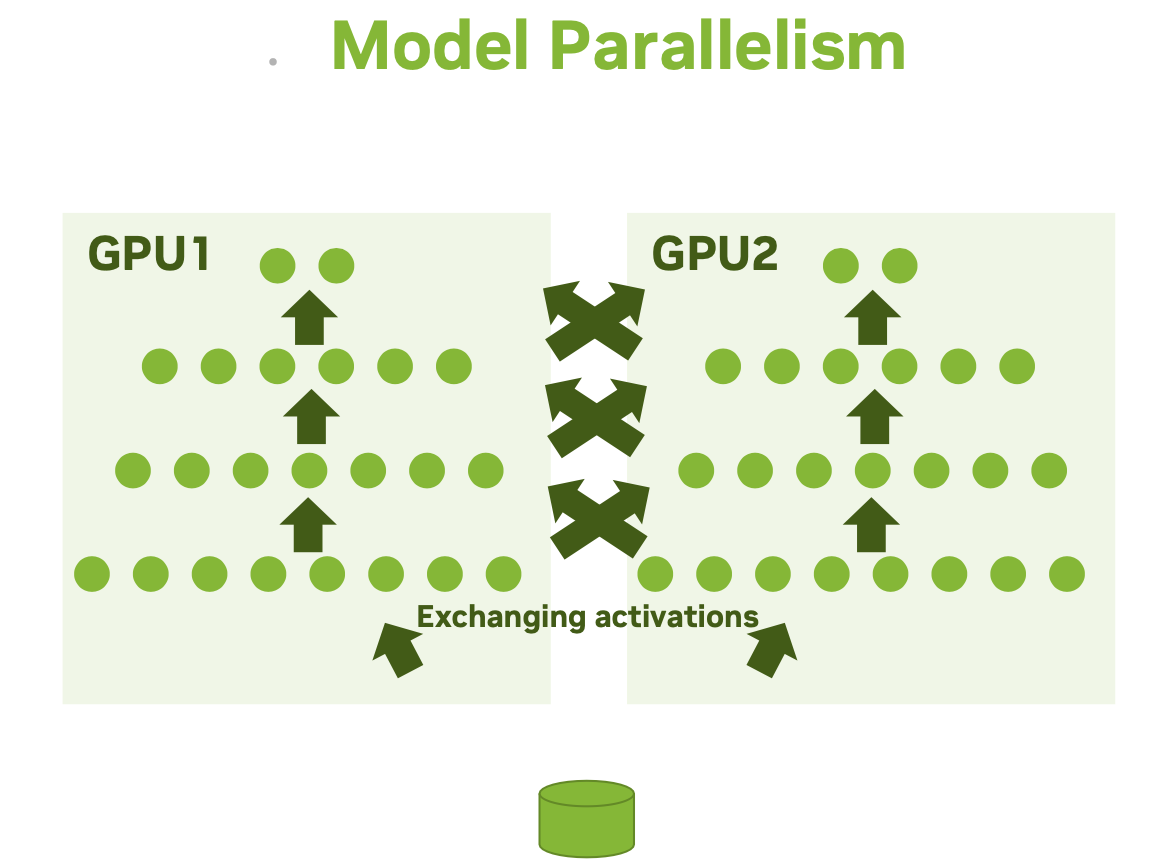
Model parallelism: Different parts of a single model run on different devices, processing a single batch of data together.
- This works best with models that have a naturally-parallel architecture, such as models that feature multiple branches.
| Data Parallelism | Model Parallelism |
|---|---|
| Allows to speed up training | All workers train on different data |
| All workers have the same copy of the model | Neural network gradients (weight changes) are exchanged |
| Allows for a bigger model | All workers train on the same data |
| Parts of the model are distributed across GPUs | Neural network activations are exchanged |
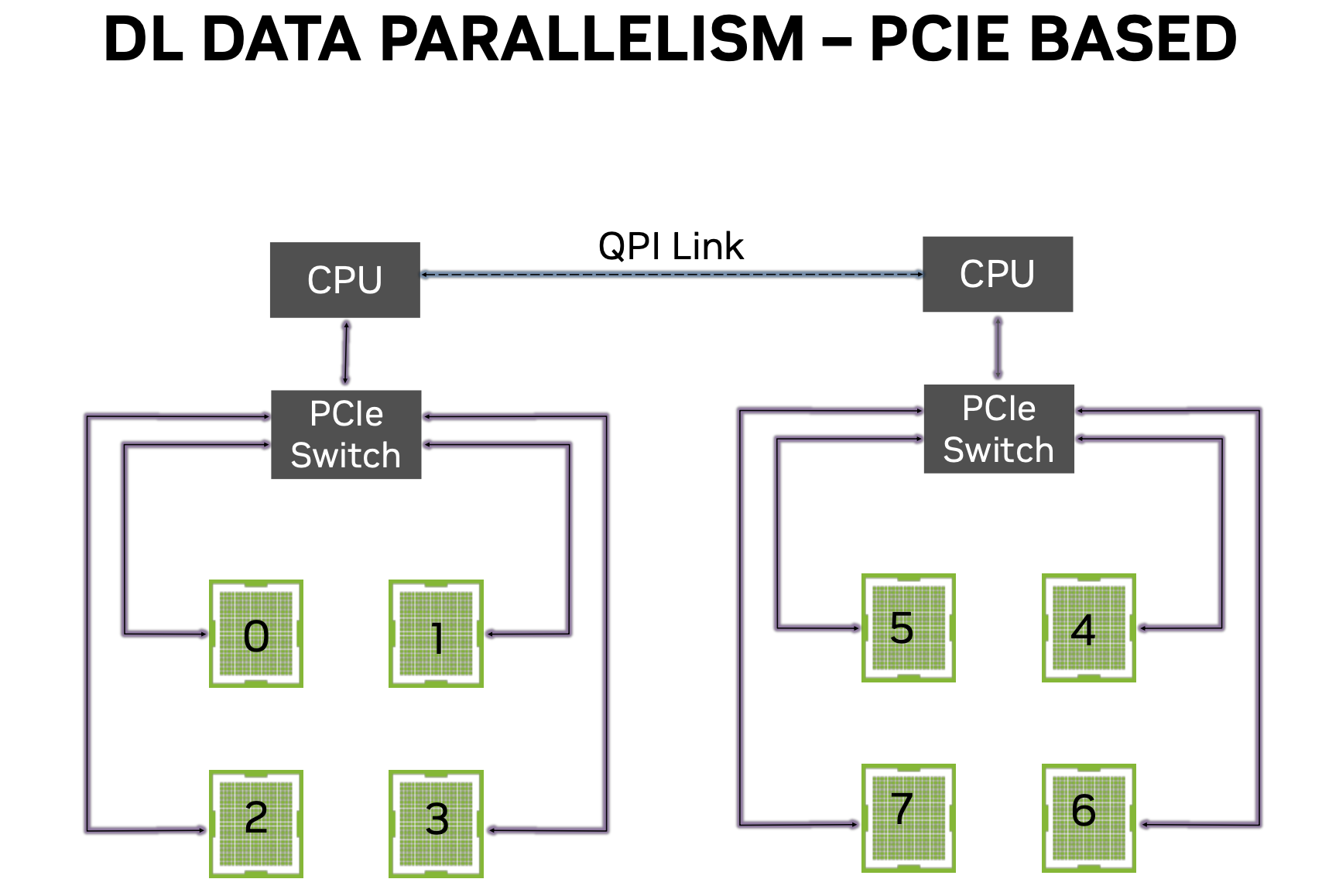
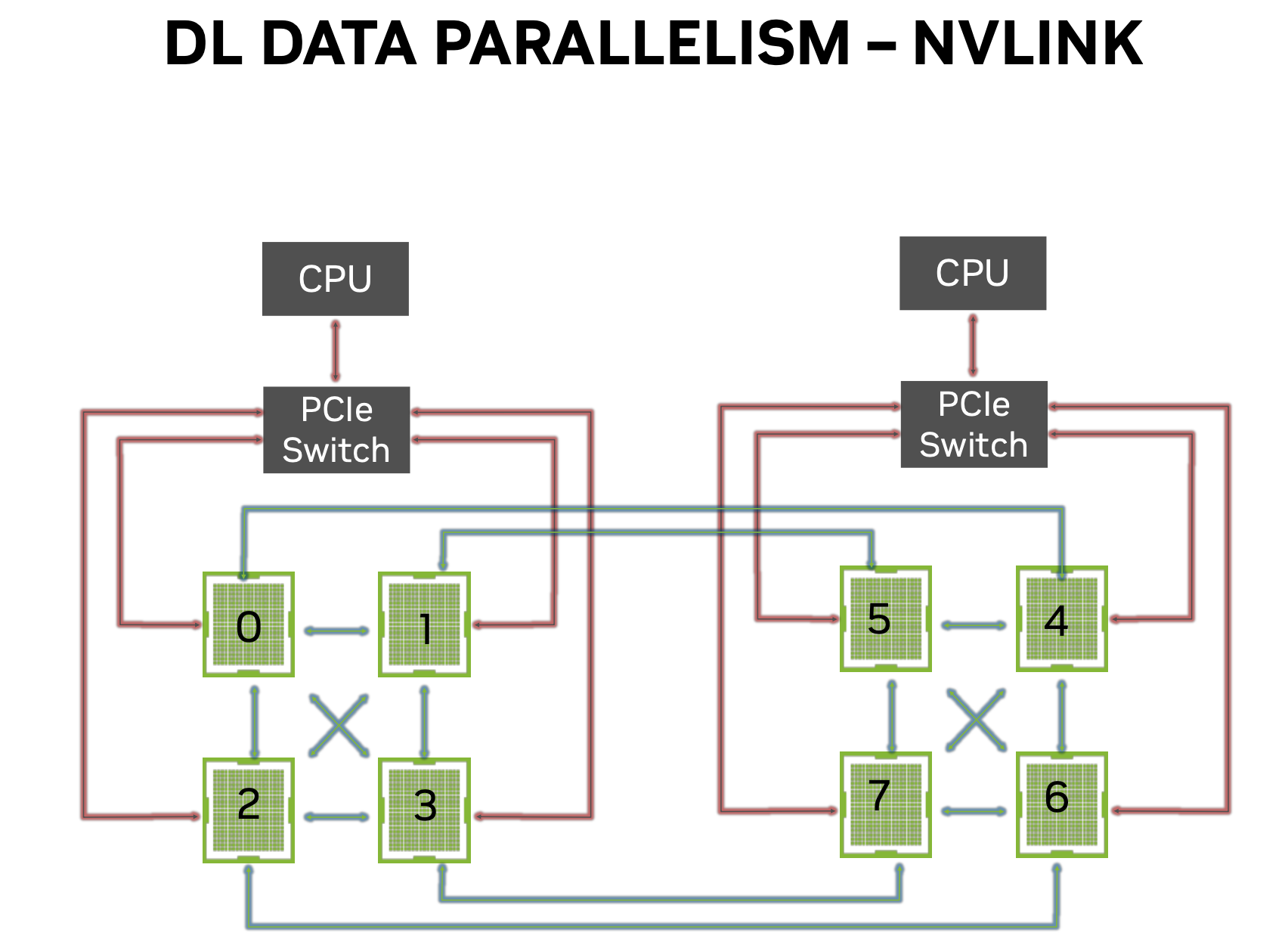
Tensorflow Example: Synchronous Data Parallelism
This guide focuses on data parallelism, in particular synchronous data parallelism, where the different replicas of the model stay in sync after each batch they process. Synchronicity keeps the model convergence behavior identical to what you would see for single-device training.
In TensorFlow we use the tf.distribute API to train Keras models on multiple GPUs. There are two setups:
-
Single host, multi-device training. This is the most common setup for researchers and small-scale industry workflows.
-
Multi-worker distributed training. This is a setup for large-scale industry workflows, e.g. training high-resolution image classification models on tens of millions of images using 20-100 GPUs.
Single Host, Multi GPUs
Each device will run a copy of your model (called a replica ).
At each step of training:
- The current batch of data (called global batch ) is split into e.g., 4 different sub-batches (called local batches ).
- Each of the 4 replicas independently processes a local batch; forward pass, backward pass, outputting the gradient of the weights.
- The weight updates from local gradients are merged across the 4 replicas.
In practice, the process of synchronously updating the weights of the model replicas is handled at the level of each individual weight variable. This is done through a mirrored variable object.
Coding: General Steps
- Design the Model
- Read in the data (recommended to use
tf.data) - Create a Mirrored Strategy
- Open a Strategy Scope
- Train the Model
- Evaluate the Model
- Display the results
Activity: Distributed TensorFlow Program
Make sure that you can run the TF code:
- TF_CNN_MultiGPU.ipynb
Pytorch Example: Data Parallel
https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
Multi-GPU, Distributed Data Parallel (DDP)
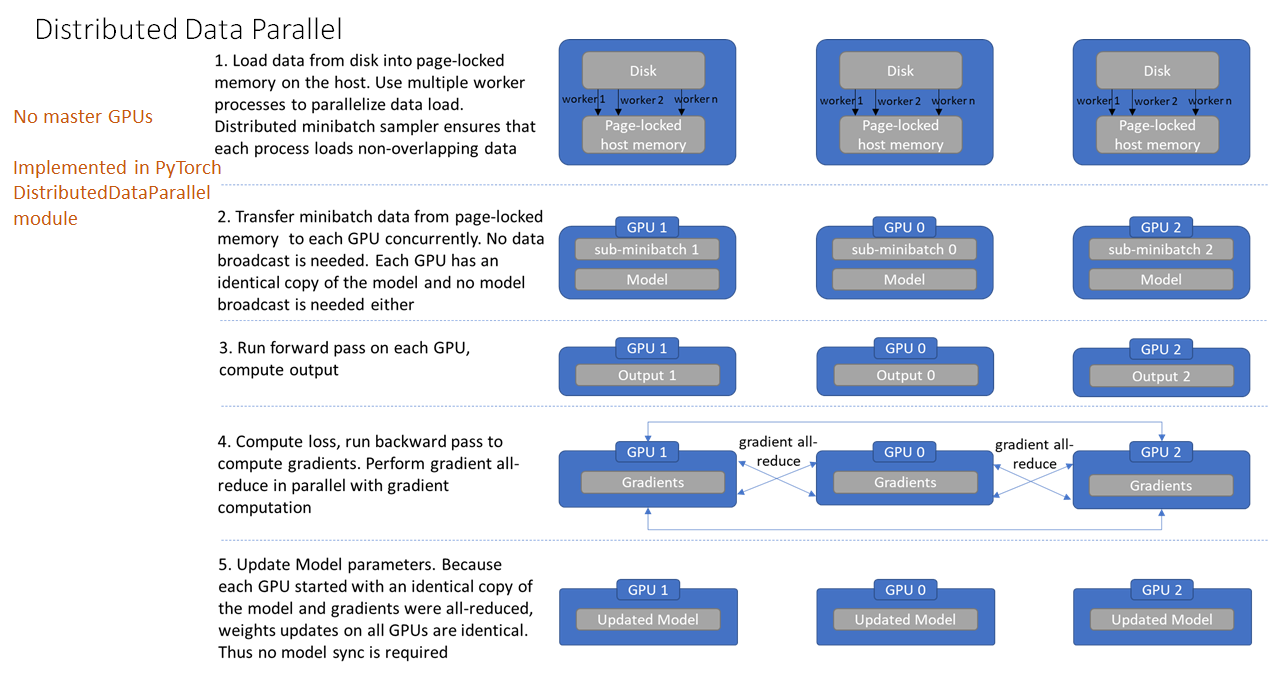
- Do not use DataParallel (increased overhead, runs on threads) in PyTorch for anything since it gives poor performance relative to DistributedDataParallel (runs on processes).
- Pytorch’s Model Parallel Best Practices: https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html
- Distributed Data Parallel video in pytorch: https://www.youtube.com/watch?v=TibQO_xv1zc
- DDP is only applied when training, no effect during validation or evaluation
- DataParallel is very easy to use and handles * everything for you, but not optimized DDP involves more coding and adjustments, but more code optimized and hence significant speedup, more salable to multiple machines and flexibility.
Coding: General Steps
- Design the Model
- Set up the Ranks
- Read in the Data
- Train the Model
- Evaluate the Model
Activity: Distributed PT Program
Make sure that you can run the PT code:
- PT_CNN_MultiGPU.py
- PT_CNN_MultiGPU.slurm
Pytorch Lightning Example: Data parallel
https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
PyTorch Lightning
PyTorch Lightning wraps PyTorch to provide easy, distributed training done in your choice of numerical precision.
To convert from PT to PTL:
- Restructure the code by moving the network definition, optimizer and other code to a subclass of L.LightningModule.
- Remove
.cuda()and.to()calls since Lightning code is hardware agnostic
Once these changes have been made one can simply choose how many nodes or GPUs to use and Lightning will take care of the rest. One can also use different numerical precisions (fp16, bf16). There is tensorboard support and model-parallel training.
Activity: Distributed PT-Lightning Program
Make sure that you can run the PyTorch-Lightning code:
- PTL_multiGPU.slurm
- PTL_multiGPU.py