GPU Overview
Graphics Processing Units (GPUs), originally developed for accelerating graphics rendering, can dramatically speed up any simple but highly parallel computational processes. GPGPU is a shorthand often used for “General-Purpose Computing on Graphics Processing Devices.”
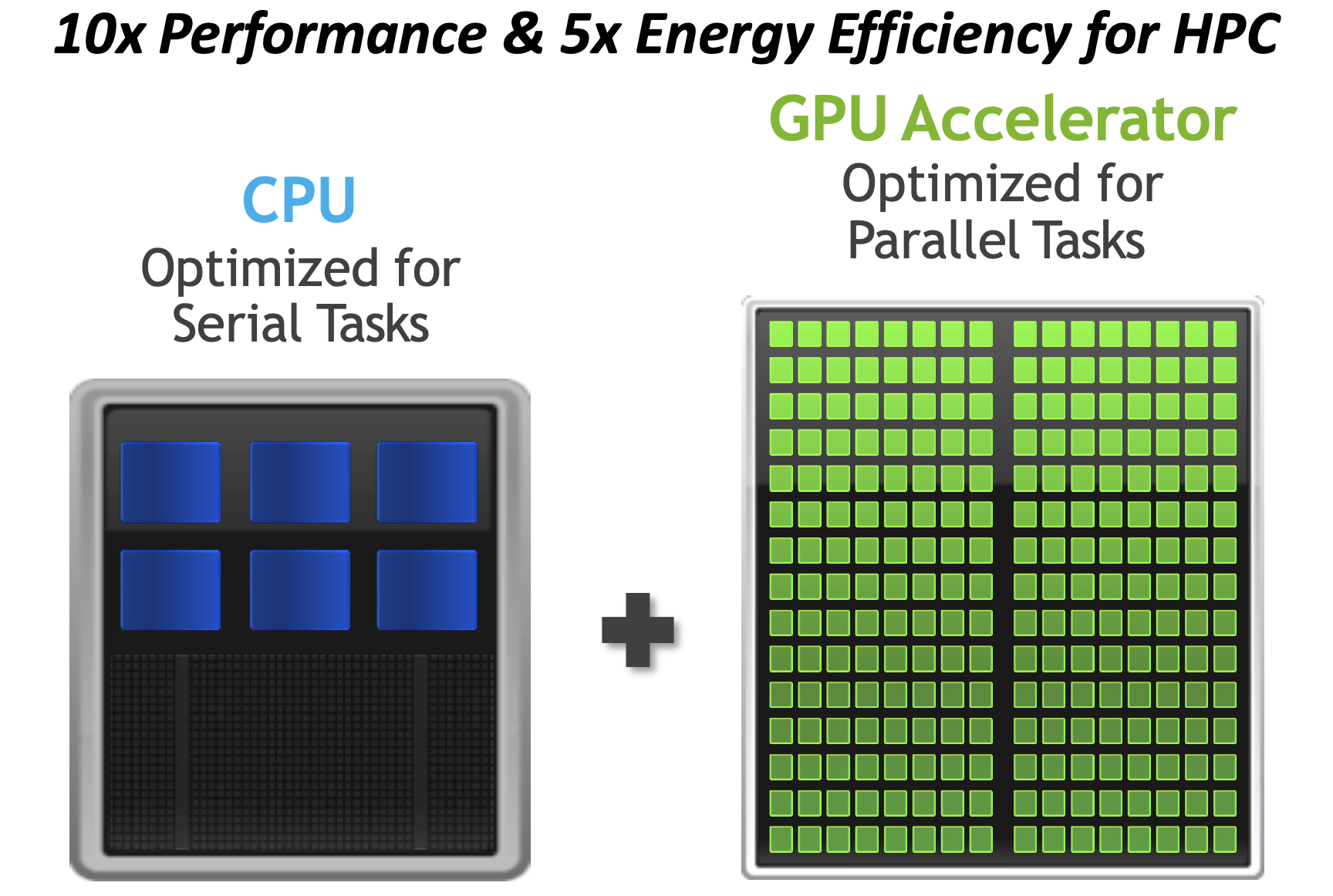
CPU versus GPU
| CPU | GPU |
|---|---|
| Several Cores (100-1) | Many Cores (103-4) |
| Generic Workload (Complex & Serial Processing) | Specific Workload (Simple & Highly Parallel) |
| Up to 1.5 TB / node on UVA HPC | Up to 80 GB /device on UVA HPC |
- Integrated GPU vs Discrete GPUs:
- Integrated GPUs are used mostly for graphics rendering and gaming
- Dedicated GPUs are designed for intensive computations
Like a CPU, a GPU has a hierarchical structure with respect to both the execution units and memory. A warp is a unit of 32 threads. NVIDIA GPUs impose a limit of 1024 threads per block. Some integral number of warps are grouped into a streaming multiprocessor (SM) and there are tens of SMs per GPU. Each thread has its own memory and there is limited shared memory between a block of threads. Finally, there is also the global memory which is accessible to each grid or collection of blocks.
Vendors and Types
- NVIDIA, AMD, Intel
- Datacenter : K80, P100, V100, A100, H100 (NVIDIA); MI300A, MI300X (AMD)
- Workstations: A6000, Quadro (NVIDIA)
- Gaming: GeForce RTX 20xx, 30xx, 40xx (NVIDA), Radeon (AMD)
- Laptops and desktops: GeForce (NVIDIA), Radeon (AMD), Iris (Intel)
Programming GPUs
Several libraries and programming models have been developed to program GPUs.
- CUDA
- CUDA is a parallel computation platform, developed by NVIDIA, for general-purpose programming on NVIDIA hardware.
- HIP
- HIP is a programming interface from AMD that allows developers to target either NVIDIA or AMD hardware.
- OpenCL
- OpenCL is a more general parallel computing platform, developed by Apple. It allows software to access CPUs, GPUs, FPGAs, and other devices.
- SYCL
- SYCL started as an outgrowth of OpenCL but is now independent of it.
- Kokkos
- Kokkos is another programming model that attempts to be device-independent. It can target multicore programming (OpenMP), CUDA, HIP, and SYCL.
Most of these programming paradigms can be used from Python, but nearly all machine learning/deep learning packages are based on CUDA and will only work with NVIDIA GPUs.
GPU Computing
- For certain workloads like image processing, training artificial neural networks and solving differential equations, a GPU-enabled code can vastly outperform a CPU code. Algorithms that require lots of logic such as “if” statements tend to perform better on the CPU.
- Steps required to execute a function (kernel) on a GPU:
- copy the input data from the CPU memory to the GPU memory
- load and execute the GPU kernel on the GPU
- copy the results from the GPU memory to CPU memory
- Depending on the DL framework, some of these steps may be automatically done.
- Recently, manufacturers have incorporated specialized units on the GPU called Tensor Cores (NVIDIA) or Matrix Cores (AMD) to perform certain operations in less than single precision.
Note: This is particularly beneficial to researchers training artificial neural networks or, more generally, cases where matrix-matrix multiplications and related operations dominate the computation time. Modern GPUs, with or without these specialized units, can be used in conjunction with a CPU to accelerate scientific codes. https://github.com/PrincetonUniversity/gpu_programming_intro/ GPU accelerated libraries. https://developer.nvidia.com/gpu-accelerated-libraries As with the CPU, a GPU can perform calculations in single precision (32-bit) faster than in double precision (64-bit)
Computational Graphs
Computational graphs help to break down computations. For example, the graph for $y=(x1+x2) \times (x2 - 5)$ is

Why Use GPUs in DL?
Data flows in neural networks can be efficiently implemented by computational graphs . This is the case with popular frameworks like TensorFlow and PyTorch.
- With deep learning models, you can have hundreds of thousands of computational graphs.
- A GPU can perform a thousand or more of the computational graphs simultaneously. This will speed up your program significantly.
- New GPUs have been developed and optimized specifically for deep learning.
- All the major deep learning Python libraries (Tensorflow, PyTorch, Keras, Caffe,…) support the use of GPUs and allow users to distribute their code over multiple GPUs.
GPUs in DL
- Scikit-learn does not support GPU processing.
- Deep learning acceleration is furthered with Tensor Cores in NVIDIA GPUs.
- Tensor Cores accelerate large matrix operations by performing mixed-precision computing.
- Tensor Cores accelerate math and reduce the memory traffic and consumption.
- If you’re not using a neural network as your machine learning model you may find that a GPU doesn’t improve the computation time.
- If you are using a neural network but it is very small then a GPU will not be any faster than a CPU - in fact, it might even be slower.
GPU Profiling
jupyterlab-nvdashboard(GPU Dashboards)nvidia-smi- only a measure of the fraction of the time that a GPU kernel is running on the GPU. Nothing about how many CUDA cores are being used or how efficiently the GPU kernels have been written.
Line_profilerfor any python code (PyTorch and TensorFlow).- Nsight Systems(
nsys) for profiling GPU codes. It produces a timeline and can handle MPI but produces a different set of profiling data for each MPI process. - Nsight Compute(
ncu) to look closely at the behavior of specific GPU kernels. Nsysandncuare more accurate measures of GPU utilization.- Additional information can be found: https://researchcomputing.princeton.edu/support/knowledge-base/gpu-computing
For codes used by large communities, one can generally associate GPU utilization with overall GPU efficiency.
GPU Utilization
- If there is zero GPU utilization…
- Is code GPU enabled?
- Is software environment properly configured?
- Does code spend a long time transferring data between CPU and GPU?(e.g. during interactive jobs)
- If there is low GPU utilization…
- There may be misconfigured application scripts.
- You may be using high end GPU for codes that do not have enough work to keep the GPU busy. Using an A100 GPU for a job that could be handled sufficiently by a P100 GPU might lead to underutilization.
- You may be training deep learning models while only using a single CPU core. Frameworks like PyTorch and TensorFlow often show significant performance benefits when multiple CPU cores are utilized for data loading.
- You may be using too many GPUs for a job. You can find the optimal number of GPUs and CPU-cores by performing a scaling analysis.
- You may be running a code written to work for a single GPU on multiple GPUs.
- Writing output files to slow storage systems instead of scratch or GPFS, can also reduce GPU utilization.
Make sure the software environment is configured properly. For hyperparameter tuning, consider using a job array. This will allow you to run multiple jobs with one sbatch command. Each job within the array trains the network using a different set of parameters.
UVA-NVIDIA DGX BasePOD
- 10 DGX A100 nodes
- 8 NVIDIA A100 GPUs.
- 80 GB GPU memory options.
- Dual AMD EPYC™️; nodes: Series 7742 CPUs, 128 total cores, 2.25 GHz (base), 3.4 GHz (max boost).
- 2 TB of system memory.
- Two 1.92 TB M.2 NVMe drives for DGX OS, eight 3.84 TB U.2 NVMe drives forstorage/cache.
- Advanced Features:
- NVLink for fast multi-GPU communication
- GPUDirect RDMA Peer Memory for fast multi-node multi-GPU communication
- GPUDirect Storage with 200 TB IBM ESS3200 (NVMe) SpectrumScale storage array
- Ideal Scenarios:
- Job needs multiple GPUs on a single node or multi node
- Job (single or multi-GPU) is I/O intensive
- Job (single or multi-GPU) requires more than 40GB of GPU memory
Always try to use the CUDA Toolkit 11.x and cuDNN 8.x since they are needed to take full advantage of the A100.
GPU Access on UVA HPC
- General
- GPUs available in both interactive and gpu partition, GPU type and number can be specified.
- POD nodes
- POD nodes are contained in the gpu partition with a specific Slurm constraint.
- Slurm script:
#SBATCH -p gpu
#SBATCH --gres=gpu:a100:X # X number of GPUs
#SBATCH -C gpupod
- Open OnDemand
--constraint=gpupod