Coding a Decision Tree
The Data
- For our first example, we will be using a set of measurements taken on various red wines.
- The data set is from
- P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis. Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547-553, 2009.
- The data is located at
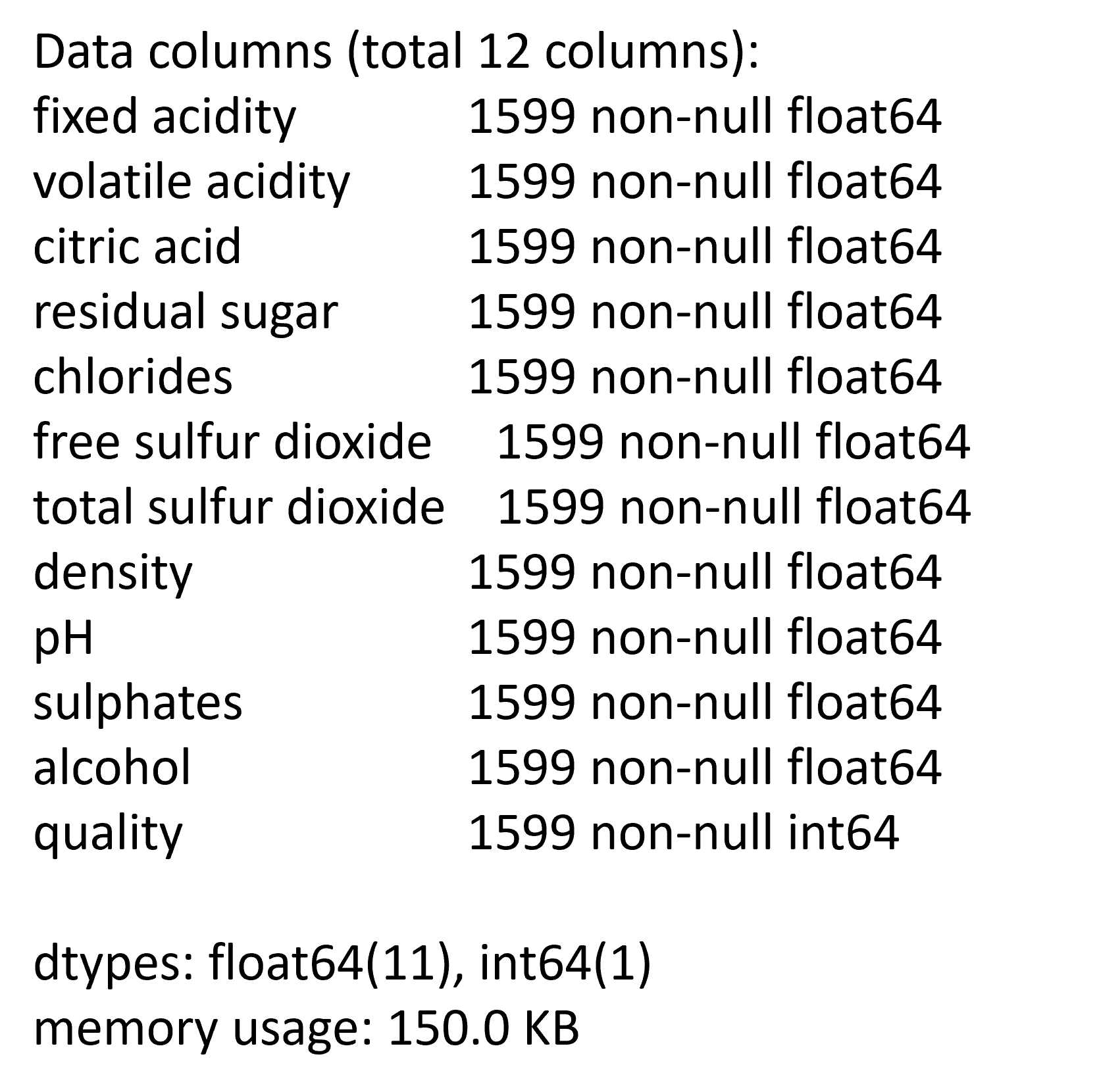
- There are 12 measurements, taken on 1599 different red wines.
Attribute Summary
Question: Can we predict the quality of the wine from the attributes?
Coding Decision Trees: General Steps
- Load the decision tree packages
- Read in the data
- Identify the target feature
- Divide the data into a training set and a test set.
- Fit the decision tree model
- Apply the model to the test data
- Display the confusion matrix
1. Load Decision Tree Package
from sklearn import tree
2. Read in the data
import pandas as pd
data_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
wine = pd.read_csv(data_url, delimiter=';')
print(wine.info())
3. Identify the target feature
#Split the quality column out of the data
wine_target = wine['quality']
wine_data = wine.drop('quality', axis=1)
For the functions that we will be using, the target values (e.g., quality) must be a separate object.
4. Divide the Data
from sklearn import model_selection
test_size = 0.30
seed = 7
train_data, test_data, train_target, test_target = model_selection.train_test_split(wine_data,
wine_target, test_size=test_size,
random_state=seed)
5. Fit the Decision Tree Model
model = tree.DecisionTreeClassifier()
model = model.fit(train_data, train_target)
6. Apply the Model to the Test Data
prediction = model.predict(test_data)
7. Display Confusion Matrix
row_name ="Quality"
cm = pd.crosstab(test_target, prediction,
rownames=[row_name], colnames=[''])
print(' '*(len(row_name)+3),"Predicted ", row_name)
print(cm)
Activity: Decision Tree Program
Make sure that you can run the decisionTree code: 01_Decision_Tree.ipynb