Optimizing LLMs with Fine-Tuning
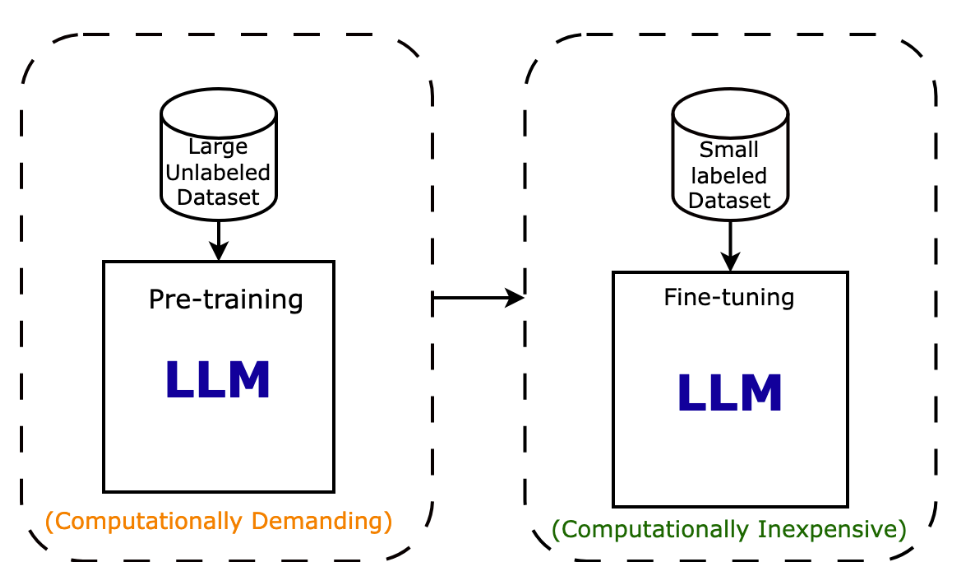
Fine-tuning builds on a pre-trained language model (LLM) by using a smaller, labeled dataset to specialize and improve its performance for a specific task. Pre-training requires a large dataset and is computationally demanding, but fine-tuning is much less resource-intensive and allows models to adapt to domain-specific needs efficiently.
Example:
The model distilbert-base-uncased was pre-trained on BookCorpus and English Wikipedia, about 25 GB of data.
The model distilbert-base-uncased-finetuned-sst-2-english was fine-tuned on the Stanford Sentiment Treebank (SST-2), about 5 MB of data.